

Para que su sitio web aparezca en los resultados de búsqueda, Google debe rastrearlo e indexarlo. Este proceso permite a Google descubrir el contenido de su sitio web, comprender lo que hay en la página y mostrar sus páginas en los resultados de búsqueda adecuados.
Para ayudar a Google a rastrear sus páginas, debe utilizar un archivo robots.txt. En esta página, vamos a responder a todas sus preguntas candentes sobre los archivos robots.txt, incluyendo:
- ¿Qué es un archivo robots.txt?
- ¿Por qué es importante el archivo robots.txt?
- ¿Cómo implemento robots.txt?
Siga leyendo para obtener más información sobre robots.txt.
¿Qué es robots.txt?
Robots.txt es un archivo que indica a los motores de búsqueda qué páginas deben rastrear y cuáles deben evitar. Utiliza instrucciones de "permitir" y "no permitir" para guiar a los rastreadores hacia las páginas que desea indexar.
Ejemplo de Robots.txt
¿Qué aspecto tiene un archivo robots.txt? Cada archivo robots.txt tiene un aspecto diferente en función de lo que permita o no permita rastrear Google.
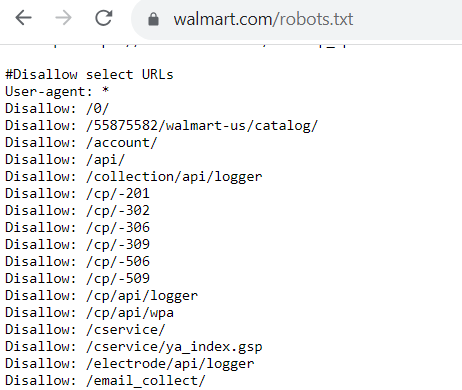
Si hay páginas que sí permite rastrear a los robots, el código tendrá este aspecto:
User-agent: Googlebot
Allow: /
El agente de usuario es el bot al que permite (o no) rastrear su sitio web. En este ejemplo de robots.txt, está permitiendo que Googlebot rastree páginas de su sitio web.
Ahora, si no quieres que un bot rastree las páginas de tu sitio web, el código tiene este aspecto:
User-agent: Bingbot
Disallow: /
Para este ejemplo de robots.txt, este código indica que Bingbot no puede rastrear páginas de un sitio web.
¿Por qué es importante el archivo robots.txt?
Entonces, ¿por qué es importante el archivo robots.txt? ¿Por qué debe preocuparse por integrar este archivo en su sitio web?
He aquí algunas razones por las que robots.txt es crucial para su estrategia de optimización de motores de búsqueda (SEO):
1. Evita que su sitio web se sature
Una de las principales razones para implementar un archivo robots.txt es evitar que su sitio web se sobrecargue con solicitudes de rastreo.
Con el archivo robots.txt en su lugar, ayuda a gestionar el tráfico de rastreo en su sitio web para que no abrume y ralentice su sitio web.
Google enviará solicitudes de rastreo para rastrear e indexar páginas de su sitio web; puede enviar docenas de solicitudes a la vez. Con el archivo robots.txt en su lugar, ayuda a gestionar el tráfico de rastreo en su sitio web para que no abrume y ralentizar su sitio web.
Un sitio web lento tiene consecuencias negativas para el SEO, ya que Google quiere ofrecer sitios web de carga rápida en los resultados de búsqueda. Por lo tanto, al implementar el archivo robots.txt, te aseguras de que Google no sobrecargue y ralentice tu sitio web mientras lo rastrea.
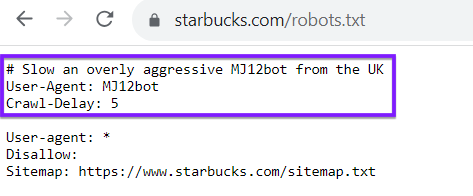
Tenga en cuenta que su archivo robots.txt no es exclusivo para rastreadores de motores de búsqueda como Google o Bing. También puede utilizar su archivo robots.txt para dirigir a los rastreadores de otros sitios web. Como ejemplo, mire el archivo robots.txt de Starbucks, que retrasa a un determinado bot:
2. Le ayuda a optimizar su presupuesto de rastreo
Cada sitio web tiene un crawl budget, que es el número de páginas que Google rastrea en un periodo de tiempo determinado. Si tiene más páginas en su sitio web de las que puede permitir dentro de su presupuesto de rastreo, las páginas no se indexarán, lo que significa que no podrán clasificarse.
Aunque su archivo robots.txt no puede impedir que las páginas se indexen, sí puede indicar a los rastreadores dónde deben invertir su tiempo.
El uso de robots.txt le ayuda a optimizar su presupuesto de rastreo. Ayuda a guiar a los robots de Google hacia las páginas que desea indexar. Aunque el archivo robots.txt no puede impedir que las páginas se indexen, sí puede mantener a los robots de rastreo centrados en las páginas que más se necesitan indexar.
3. Ayuda a impedir que los rastreadores rastreen páginas no públicas
Todas las empresas tienen páginas en su sitio web que no quieren que aparezcan en los resultados de búsqueda, como páginas de inicio de sesión y páginas duplicadas. Robots.txt puede ayudar a evitar que estas páginas aparezcan en los resultados de búsqueda y bloquea las páginas de los rastreadores.
Problemas comunes con los archivos robots.txt
A veces, los sitios web experimentan problemas al utilizar robots.txt. Un posible problema es que el archivo impida que Google (u otros motores de búsqueda) rastree su sitio web. Si descubres que algo así está ocurriendo, deberás actualizar tu archivo robots.txt para solucionarlo.
Otro posible problema es que haya datos confidenciales o privados en algún lugar de su sitio (privados para su empresa o para sus clientes) y que el archivo robots.txt no los bloquee, lo que permitiría a Google rastrearlos libremente. Se trata de una infracción grave, por lo que debe asegurarse de bloquear esos datos para que no los rastreen.
¿Cuándo se debe actualizar un archivo robots.txt?
Incluso después de crear un archivo robots.txt, es probable que necesite actualizarlo en algún momento. Pero, ¿cuándo tendría que hacerlo exactamente?
Estas son algunas ocasiones en las que podría actualizar su archivo robots.txt:
- Al migrar a un nuevo sistema de gestión de contenidos (CMS)
- Si desea mejorar la forma en que Google rastrea su sitio web
- Cuando añada una nueva sección o subdominio a su sitio web
- Cuando se cambia totalmente a un nuevo sitio web
Todos estos cambios requieren que vaya y edite su archivo robots.txt para reflejar lo que está sucediendo en su sitio.
6 consejos para hacer robots.txt para SEO con éxito
¿Está listo para implementar un archivo robots.txt en su sitio web? Aquí tienes 6 consejos que te ayudarán a hacerlo con éxito:
1. Asegúrese de que todas sus páginas importantes son rastreables
Antes de crear su archivo robots.txt, es importante identificar las páginas más importantes de su sitio web. Debe asegurarse de que esas páginas son rastreadas para que puedan aparecer en los resultados de búsqueda.
Antes de crear su archivo robots.txt, documente las páginas importantes que desea permitir que rastreen los robots de búsqueda. Estas podrían incluir páginas como su:
- Páginas de productos
- Quiénes somos
- Páginas informativas
- Entradas de blog
- Página de contacto
2. Utilice cada agente de usuario una sola vez
Cuando cree su archivo robots.txt, es importante que cada agente de usuario sólo se utilice una vez. Hacerlo de esta manera ayuda a mantener su código limpio y organizado, especialmente si hay bastantes páginas que desea no permitir.
He aquí un ejemplo de robots.txt que muestra la diferencia:
User-agent: Googlebot
Disallow: /pageurl
User-agent: Googlebot
Disallow: /loginpage
Ahora, imagine que tuviera que hacer esto para múltiples URLs. Se volvería repetitivo y haría que su archivo robots.txt fuera difícil de seguir. En su lugar, es mejor organizarlo así:
User-agent: Googlebot
Disallow: /pageurl/
Disallow: /loginpage/
Con esta configuración, todos los enlaces no permitidos se organizan bajo el agente de usuario específico. Este enfoque organizado hace que sea más fácil para usted encontrar las líneas que necesita ajustar, añadir o eliminar para bots específicos.
3. Utilice líneas nuevas para cada directiva
Cuando cree su archivo robots.txt, es crucial que ponga cada directiva en su propia línea. De nuevo, este consejo le facilitará la gestión de su archivo.
Así, cada vez que añadas un agente de usuario, debe estar en su propia línea con el nombre del bot. La siguiente línea debe tener la información de disallow o allow. Cada línea disallow subsiguiente debe estar en su propia línea.
He aquí un ejemplo de robots.txt de lo que no se debe hacer:
User-agent: Googlebot Disallow: /pageurl/ Disallow: /loginpage/
Como puede ver, hace que sea más difícil leer su robots.txt y saber lo que dice.
Si cometes un error, por ejemplo, será difícil encontrar la línea correcta para corregirlo.
Poner cada directiva en su propia línea hará más fácil hacer cambios más tarde.
4. Asegúrese de utilizar casos de uso adecuados
Si hay algo que debe saber sobre robots.txt para SEO, es que este archivo distingue entre mayúsculas y minúsculas. Debes asegurarte de utilizar las mayúsculas y minúsculas adecuadas para que funcione correctamente en tu sitio web.
En primer lugar, su archivo debe estar etiquetado como "robots.txt" en ese caso de uso.
En segundo lugar, debe tener en cuenta cualquier variación de mayúsculas en las URL. Si tiene una URL que utiliza mayúsculas, debe introducirla en su archivo robots.txt como tal.
5. Utilice el símbolo "*" para indicar la dirección
Si tiene numerosas URL bajo la misma dirección que desea impedir que rastreen los robots, puede utilizar el símbolo "*", llamado comodín, para bloquear todas esas URL a la vez.
Por ejemplo, supongamos que desea desautorizar todas las páginas relacionadas con búsquedas internas. En lugar de bloquear cada página individualmente, puede simplificar su archivo.
En lugar de que se vea así:
User-agent: *
Disallow: /search/hoodies/
Disallow: /search/red-hoodies/
Disallow: /search/sweaters
Puede utilizar el símbolo "*" para simplificarlo:
User-agent: *
Disallow: /search/*
Al aplicar este paso, se impide que los robots de los motores de búsqueda rastreen las URL de la subcarpeta "búsqueda". Utilizar el símbolo de comodín es una forma sencilla de inhabilitar páginas por lotes.
6. Utilice el "$" para simplificar la codificación
Existen numerosos trucos de codificación que puede utilizar para facilitar la creación de su archivo robots.txt. Un truco consiste en utilizar el símbolo "$" para indicar el final de una URL.
Si tiene páginas similares que desea desautorizar, puede ahorrarse tiempo utilizando el "$" para aplicarlo a todas las URL similares.
Por ejemplo, supongamos que quieres evitar que Google rastree tus vídeos. Este es el aspecto que podría tener ese código si lo hace cada uno:
User-agent: Googlebot
Disallow: /products.3gp
Disallow: /sweaters.3gp
Disallow: /hoodies.3gp
En lugar de tenerlos todos en líneas separadas, puede utilizar el "$" para desautorizarlos a todos. Se parece a esto:
User-agent: GooglebotDisallow: /*.3gp$
El uso de este símbolo indica a los rastreadores que las páginas que terminan en ".3gp" no pueden ser rastreadas.
Amplíe sus conocimientos de SEO
Añadir robots.txt a su sitio web es crucial para ayudar a Google a rastrear sus páginas sin sobrecargarlo. Es uno de los aspectos que te ayudarán a hacer SEO de forma efectiva.
Descubre más oportunidades SEO con SEO.com. Nuestra aplicación para principiantes te ofrece recomendaciones para ayudarte a escalar posiciones más rápido que tus competidores. ¡ Prueba SEO.com gratis hoy mismo!
Descubra su potencial SEO
¡Localice oportunidades en su sitio web más rápidamente y aumente su visibilidad en línea con SEO.com!

Reduzca a la mitad su tiempo de SEO
con su nueva herramienta SEO favorita y fácil de usar
Escritores
